6.3 高速アルゴリズム
- 本節では、6.2節で紹介した並べ換えのアルゴリズムよりも高速に処理ができるアルゴリズムを紹介する。ここで高速と呼んでいるものは、O(n log n)に分類できるものである。
(1) クイックソート
- クイックソートは世の中で最も速いソートアルゴリズムとして知られている。(これは、一つのCPUで順次処理を行なった場合である。最近では、計算機の機能が高まり、並列処理や分散処理が可能となっているため、複数のCPUを持った計算機上での並べ換えについては、クイックソートよりも速いアルゴリズムが提案されている。)
クイックソートは、データの分割法をソートのアルゴリズムに適用した典型なものである。データ分割法の基本原理は、
1 データのブロック分割 2 各ブロックごとの処理(並べ換え) 3 ブロックの統合であり、クイックソートでは特に1のデータの分割にアルゴリズムのよさの秘密が隠されている。例を用いてクイックソートのアルゴリズムを解説しよう。例 入力データ: 48 65 10 36 83 5 21 72
ステップ01 まず与えられたデータ列の真ん中(左から4番目)に位置する データを基準値をして定める。例では、36と基準値としよう。48 65 10 36 83 5 21 72 ^ ^ ^
ステップ02 データを左から順に基準値よりも大きいデータを捜す。まず48が見つかる。続いて、右から順に基準値よりも小さいデータを捜す。 21が見つかる。ここで、48と21を入れ替えする。現在注目しているデータの位置を次に進める(左から見ている場合は一つ右へ、右からの場合は左へ一つ進める)。21 65 10 36 83 5 48 72 ^ ^ ^
さらに、ステップ02を続けると、5と65が入れ替わる。21 5 10 36 83 65 48 72 ^ ^ ^
以下、同様な操作を繰り返し、注目している点が交差するまで行なう。すると21 5 10 36 83 65 48 72
が得られる。これは、基準値とした位置(左から4番目)を境に、左右ブロックに分割したことになる。左側には4番目のデータ(36)よりも小さいデータ、右側には大きいデータとなる。ステップ1−1 左側のブロックに対して、ステップ01,02を行なう。
21 5 10 ^ 5 21 10
よって、5と21,10とに分割できる。ステップ1−1−1 さらに、左側についてステップ01,02を行なう。この場合、5だけなのでなにもしない。
ステップ1−1−2 右側の21,10についてステップ01,02を行なう。
上記ステップ1−1−1,1−1−2により、 5 10 21 が得られる。
ステップ1−2 83,65,48,72について同様にステップ01,02を行なう。 よって、 5 10 21 36 48 65 72 83 が得られる。
基準点としたデータが、左、右いずれかのブロックに含まれる時と含まれない時がある。その詳細についてはプログラム6−4を見ていただきたい。ここでは、アルゴリズムの大体の考え方を理解できればよいと考えている。
クイックソートのプログラムは以下のようである。
/* 1 */ /* Program 6-4 */ /* 2 */ /* Quick Sort */ /* 3 */ /* 4 */ #include<stdio.h> /* 5 */ #define MaxNumber 100 /* 6 */ #define INIT 1984 /* 7 */ /* 8 */ void QuickSort( int data[], int lowert, int upper ); /* 9 */ void Outputdata( int data[], int n ); /* 10 */ void Makedata( int data[], int n ); /* 11 */ int rnd(void); /* 12 */ /* 13 */ /* 14 */ /* 15 */ main() /* 16 */ { /* 17 */ int data[MaxNumber], i; /* 18 */ /* 19 */ Makedata(data, MaxNumber); /* 20 */ QuickSort(data, 0, MaxNumber-1); /* 21 */ Outputdata(data, MaxNumber); /* 22 */ } /* 23 */ /* 24 */ void QuickSort( int data[], int upper, int lower ) /* 25 */ { /* 26 */ int mid, tmp, i, j; /* 27 */ /* 28 */ i = upper; /* 29 */ j = lower; /* 30 */ mid = data[(lower+upper)/2]; /* 31 */ do /* 32 */ { /* 33 */ while( data[i] < mid ) i++; /* 34 */ while( mid < data[j] ) j--; /* 35 */ if( i <= j ) /* 36 */ { /* 37 */ tmp = data[i]; /* 38 */ data[i] = data[j]; /* 39 */ data[j] = tmp; /* 40 */ i++; /* 41 */ j--; /* 42 */ } /* 43 */ } while( i <= j ); /* 44 */ if ( upper < j ) QuickSort(data, upper, j); /* 45 */ if ( i < lower ) QuickSort(data, i, lower); /* 46 */ } /* 47 */ /* 48 */ void Outputdata(int data[], int n) /* 49 */ { /* 50 */ int i; /* 51 */ /* 52 */ for (i=0; i < n; i++) /* 53 */ { /* 54 */ printf("%8d", data[i]); /* 55 */ } /* 56 */ } /* 57 */ /* 58 */ void Makedata( int data[], int n) /* 59 */ { /* 60 */ int i; /* 61 */ /* 62 */ for (i=0; i < n; i++) /* 63 */ data[i] = rnd(); /* 64 */ } /* 65 */ /* 66 */ int rnd(void) /* 67 */ { /* 68 */ static unsigned long mod = INIT; /* 69 */ /* 70 */ mod = (23 * mod) % 32749; /* 71 */ return mod; /* 72 */ }
関数Quicksortは、プログラム内部でさらに自分自身を関数として呼んでいる。つまり再帰的なアルゴリズムとなっている。先に示した例のデータを用いて実行の様子を表現すると、下記のような構造となっている。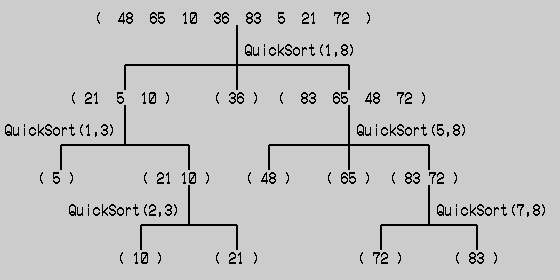
よって分割したブロックを統合すると、
5 10 21 36 48 65 72 83
となる。クイックソートの計算時間量を評価してみよう。今回は、プログラム中の37−39の実行回数をカウントすることで、オーダーを求めることにする。
1段目 QuickSort(1,n)では、入れ替えの起こる確率を1/2とすると約n/2回実行される。 2段目 QuickSort(1,n/2)、QuickSort(n/2,n)では、入れ替えの起こる確率を1/2とするとそれぞれ約n/4回実行される。二つの回数を合わせると、約n/2回の実行となる。 3段目 4つの関数QuickSort(1,n/4)、QuickSort(n/4,n/2)、QuickSort(n/2,3n/4)、QuickSort(3n/4,n)が実行されそれぞれ約n/8回の実行となる。これらを合わせると約n/2回の実行となる。 4段目 同様に考えると8回のQuickSort関数を実行し、それぞれ約n/16回実行。合わせると約n/2回の実行回数となる。 以上から、各段階では約n/2回の入れ替えが起こることがわかる。
上記分割が何回(何段まで)起こるかを考えよう。1回の関数の実行では2つに分割され、それらがさらに2つに分割される。これが1つのデータとなるまで繰り返される。よって分割の回数は、log(n)回であると言える。ここで、logとは数学の対数関数を意味し、この場合の対数の底は2である。 n=2^k(nが2のk乗)である時、k=log(n)である。
よって、プログラム37−39の実行回数は、n/2 * log(n) 回となり、プログラム4−6はO(nlogn)であると言える。これは、前節で示したO(n^2)のアルゴリズムと比較すると、非常に効率がよいことがわかる。
今回の解説では分割の基準点を中心として行なったが、先頭データを基準点とする方法もある。完全にランダムなデータに対しては、基準点をどちらに設定しても同じ計算の手間で実行される。しかし、すでに並べ替えが完了しているデータに対して、先頭のデータを基準点とする方法を適用すると、最悪ケースとなりO(n^2)の計算量となることが知られている。
演習問題
-
y=x^2 と y=x*log(x) の関数のグラフを書いてみよう(対数の底を2と考える)。グラフの増加の様子から、xがどのくらいになるとyがとてつもなく大きくなるかを調べよ。
(2)ヒープソート
ヒープ生成の例
-
初期状態: 21 ┌─────┴─────┐ 53 12 ┌───┴───┐ ┌───┴───┐ 46 87 59 40 ┌──┴──┐ 70
上記で説明した考えをもとに、データの並べ換えを行なう。実際に計算機で行なう場合、2分木を表現することは面倒なことである。そこで、今回は配列を工夫し2分木にみたてておこなう。下記のような配列を考えてみよう。
状態2:初期状態において70,40,59,87は下位にデータを持たな いので、ヒープの条件を満足していると考えられる。まず、46を 2分木の根とみたてshiftdown操作を行なう。 21 ┌─────┴─────┐ 53 12 ┌───┴───┐ ┌───┴───┐ 70 87 59 40 ┌──┴──┐ 46
状態3:状態2において70,87,59,40,46は、ヒープの条件を 満足していると考えられる。次に12を2分木の根とみたて shiftdown操作を行なう。 21 ┌─────┴─────┐ 53 59 ┌───┴───┐ ┌───┴───┐ 70 87 12 40 ┌──┴──┐ 46
状態4:状態3において59,70,87,12,40,46は、ヒープの 条件を満足していると考えられる。次に53を2分木の根とみたて shiftdown操作を行なう。 21 ┌─────┴─────┐ 87 59 ┌───┴───┐ ┌───┴───┐ 70 53 12 40 ┌──┴──┐ 46
状態5:状態4において87,59,70,53,12,40,46は、ヒー プの条件を満足していると考えられる。次に21についてshiftdown 操作を行なう。 87 ┌─────┴─────┐ 70 59 ┌───┴───┐ ┌───┴───┐ 46 53 12 40 ┌──┴──┐ 21 よって、任意に与えた2分木に対して、ヒープが構成できた。
便宜的に、配列の区切りを入れている所と入れていない所がある。これは、2分木の階層を明らかにするためである。上記配列は、下記の2分木を表現していることを理解していただきたい。
h(1) │ ┌────────┴────────┐ h(2) h(3) ┌─────┴─────┐ ┌─────┴─────┐ h(4) h(5) h(6) h(7) ┌──┴──┐ ┌──┴──┐ h(8) h(9) h(10)
アルゴリズムの進行とともにヒープが縮小するため、配列の後尾が空となる。そこで、ヒープから取り出したデータを配列の後ろから順に詰めて行くことにより、ソートが完了した時点で、配列内にデータが並べ替わっていることになる。 配列の場合の例
(1)初期ヒープの生成
初期データ: 21 53 12 46 87 59 40 70
状態2: 初期状態において70,40,59,87は下位にデータを持たないので、ヒープの条件を満足していると考えられる。まず、46を2分木の根とみたてshiftdown操作を行なう。 21 53 12 70 87 59 40 46
状態3: 状態2において70,87,59,40,46は、ヒープの条件を満足していると考えられる。次に12を2分木の根とみたてshiftdown操作を行なう。 21 53 59 70 87 12 40 46
状態4: 状態3において59,70,87,12,40,46は、ヒープの条件を満足していると考えられる。次に53を2分木の根とみたてshiftdown操作を行なう。 21 87 59 70 53 12 40 46
状態5: 状態4において87,59,70,53,12,40,46は、ヒープの条件を満足していると考えられる。次に21を2分木の根とみたてshiftdown操作を行なう。 87 70 59 46 53 12 40 21
(2)ソート
初期状態: 87 70 59 46 53 12 40 21
状態2: 先頭の87(h(1))を取り出しす。 21(h(k))を2分木の根(h(1))に移動し、shiftdown操作を行なう。 取り出した87は配列の最後に格納する。 70 53 59 46 21 12 40 87
状態3: 先頭の70(h(1))を取り出しす。40を2分木の根(h(1))に移動し、shiftdown操作を行なう。 取り出した70は配列の最後から2番目にに格納する。 59 53 40 46 21 12 70 87
状態4: 先頭の59(h(1))を取り出す。12を2分木の根(h(1))に移動し、shiftdown操作を行なう。 取り出した59は配列の最後から3番目に格納する。 53 46 40 12 21 59 70 87
状態5: 以下同様な操作を繰り返す。 46 21 40 12 53 59 70 87
状態6: 39 20 12 46 53 59 70 87
状態7: 21 12 40 46 53 59 70 87
状態8: 12 21 40 46 53 59 70 87
上記考えをプログラムすると、プログラム6−5のようになる。
/* 1 */ /* Program 6-5 */ /* 2 */ /* Heap Sort */ /* 3 */ /* 4 */ #include<stdio.h> /* 5 */ #define MaxNumber 100 /* 6 */ #define INIT 1984 /* 7 */ /* 8 */ void HeapSort( int data[], int n ); /* 9 */ void Shiftdown(int data[], int top, int bottom); /* 10 */ void Outputdata( int data[], int n ); /* 11 */ void Makedata( int data[], int n ); /* 12 */ int rnd(void); /* 13 */ /* 14 */ /* 15 */ /* 16 */ main() /* 17 */ { /* 18 */ int data[MaxNumber], i; /* 19 */ /* 20 */ Makedata(data, MaxNumber); /* 21 */ HeapSort(data, MaxNumber-1); /* 22 */ Outputdata(data, MaxNumber); /* 23 */ } /* 24 */ /* 25 */ void HeapSort( int data[], int n ) /* 26 */ { /* 27 */ int top, bottom, tmp; /* 28 */ /* 29 */ bottom = n/2 +1; /* 30 */ top = n; /* 31 */ while ( bottom > 0 ) /* 32 */ { /* 33 */ bottom--; /* 34 */ Shiftdown( data, top, bottom ); /* 35 */ } /* 36 */ while ( top > 0 ) /* 37 */ { /* 38 */ tmp = data[0]; /* 39 */ data[0] = data[top]; /* 40 */ data[top] = tmp; /* 41 */ top--; /* 42 */ Shiftdown( data, top, bottom ); /* 43 */ } /* 44 */ } /* 45 */ /* 46 */ void Shiftdown(int data[], int top, int bottom) /* 47 */ { /* 48 */ int i, tmp; /* 49 */ /* 50 */ i = 2 * bottom; /* 51 */ while( i <= top ) /* 52 */ { /* 53 */ if( i < top && data[i+1]>data[i] ) i++; /* 54 */ if( data[bottom]>=data[i] ) break; /* 55 */ tmp = data[bottom]; /* 56 */ data[bottom] = data[i]; /* 57 */ data[i] = tmp; /* 58 */ bottom = i; /* 59 */ i = 2 * bottom; /* 60 */ } /* 61 */ } /* 62 */ /* 63 */ void Outputdata(int data[], int n) /* 64 */ { /* 65 */ int i; /* 66 */ /* 67 */ for (i=0; i < n; i++) /* 68 */ { /* 69 */ printf("%8d", data[i]); /* 70 */ } /* 71 */ } /* 72 */ /* 73 */ void Makedata( int data[], int n) /* 74 */ { /* 75 */ int i; /* 76 */ /* 77 */ for (i=0; i < n; i++) /* 78 */ data[i] = rnd(); /* 79 */ } /* 80 */ /* 81 */ int rnd(void) /* 82 */ { /* 83 */ static unsigned long mod = INIT; /* 84 */ /* 85 */ mod = (23 * mod) % 32749; /* 86 */ return mod; /* 87 */ }
31−35で初期のヒープを作成し、36−43でヒープの再構成を行なっている。ヒープソートの計算時間量は、
O(n log n) である。簡単に、理由を述べる。主に関数shiftdown内の入れ換えの回数に着目してやればよい。つまり、55−57の実行回数である。2分木の根から順に、下位の部分木の頂点にあるデータと比較するため、1回のshiftdown操作では、log(n)回 (logとは対数関数であり、この場合2分木であるため対数の底を2として考えている。nはデータの個数である。)比較を行なっていることになる。関数shiftdownの呼ばれる回数は、データの個数nに比例している。そのため、
n*log(n) が得られる。基本的な考え方は以上の通りである。詳細は、演習問題としよう。
ヒープソートは、クイックソートに比べて平均約2倍のスピードを要する。しかしながら、ヒープソートは、どのような配置のデータにも常に
O(n log n) で処理がなされ、外部記憶装置内のデータにも適用可能なことから、利用度の高いアルゴリズムであるといえる。
-
ヒープ(heap)とは、以下の条件を満たす2分木のことである。2分木とは、1つの頂点から2本以下の枝が出ている木のことであり、計算機分野では重要な構造の1つである。2分木の構成方法や応用については第7節を予定している。
ヒープ:2分木の各頂点には次の2式を満たさなければならない。
1. h(i) ≧ h(2i) i=1,2,3,...
2. h(i) ≧ h(2i+1) i=1,2,3,...
つまり、2分木の各頂点に位置するデータの値は、常に上に位置するデータの値以下になっていなければならない。
例 h(1) │ ┌───────┴───────┐ h(2) h(3) ┌────┴────┐ ┌───┴───┐ h(4) h(5) h(6) h(7) ┌──┴──┐ ┌──┴──┐ h(8) h(9) h(10)
この場合、h(1)≧h(2),h(3) h(2)≧h(4),h(5) h(3)≧h(6),h(7) h(4)≧h(8),h(9) h(5)≧h(10)である。ヒープによる並べ換えは、ヒープがすでに与えられているものとして、ヒープが空になるまで以下の2つのステップを繰り返す。
ステップ1 最上位のh(1)を取り出す。
ステップ2 残りのヒープh(2),h(3),...,h(n)をヒープに再構成する。
再構成は、以下のa), b) にしたがって行なう。
a) h(1)の位置にh(n)を移動する。もとのh(n)は削除する。
b) h(1)の位置からshiftdown操作を行なう。
shiftdown操作: h(i) < max(h(2i), h(2i+1))のとき、
h(2i)とh(2i+1)の大きい方をh(i)と交換する。
交換したところから、同様な操作を繰り返す。
shiftdown操作の例を以下に示す。
初期状態: 84 ┌─────┴─────┐ 73 66 ┌───┴───┐ ┌───┴───┐ 22 37 11 49 ┌──┴──┐ 6状態2:初期状態においてh(1)である84を取り出し、h(n)である6をh(1)の位置に移動する。
6 ───>84 ┌─────┴─────┐ 73 66 ┌───┴───┐ ┌───┴───┐ 22 37 11 49 ┌──┴──┐ h(1)の位置(6)からshiftdown操作を行なう。 73 ───>84 ┌─────┴─────┐ 6 66 ┌───┴───┐ ┌───┴───┐ 22 37 11 49 73 ───>84 ┌─────┴─────┐ 37 66 ┌───┴───┐ ┌───┴───┐ 22 6 11 49よって、取り除かれたデータは並べ換えが済んでいる。
状態3:h(1)である73を取り去り、h(n)である49をh(1)の位置に移動する。 49 ───> 73 84 ┌─────┴─────┐ 6 66 ┌───┴───┐ ┌───┴───┐ 22 37 11 h(1)からshiftdown操作を行なう。 66 ───> 73 84 ┌─────┴─────┐ 6 49 ┌───┴───┐ ┌───┴───┐ 22 37 11
状態4:66を取り除き、11をh(1)位置に移動し、shiftdown操作を行なう。 49 ───> 66 73 84 ┌─────┴─────┐ 6 11 ┌───┴───┐ ┌───┴───┐ 22 37
状態5:以下同様な操作を繰り返す。 37 ───> 49 66 73 84 ┌─────┴─────┐ 6 11 ┌───┴───┐ ┌───┴───┐ 22
状態6: 22 ───> 37 49 66 73 84 ┌─────┴─────┐ 6 11
状態7: 11 ───> 22 37 49 66 73 84 ┌─────┴─────┐ 6
状態8: 6 ───> 11 22 37 49 66 73 84 ┌─────┴─────┐
次に、最初のヒープを構成する方法について述べる。
| ステップ1 | 任意の2分木を与える。この2分木の各頂点のデータの値をそれぞれ h(1),h(2),h(3),...をする。 |
| ステップ2 |
この2分木で、枝が1本も出ていない頂点、つまり h(k),h(k+1),...,h(n) (k=[n/2]+1) は、下位にデータを持たないため、ヒープの条件が満足されていると解釈できる。 |
| ステップ3 | 残りの頂点をh(k-1),h(k-2),...,h(1)の順にとりあげ、その頂点を下位の部分木の根(h(1))とみたてヒープを構成していく。その際には、前記のshiftdown操作を使う。 |
(3)シェルソート
プログラム6−6
/* 1 */ /* Program 6-6 */ /* 2 */ /* Shell Sort */ /* 3 */ /* 4 */ #include<stdio.h> /* 5 */ #define MaxNumber 100 /* 6 */ #define INIT 1984 /* 7 */ /* 8 */ void ShellSort(int data[], int n); /* 9 */ void SimpleInsertion( int data[], int skip, int n ); /* 10 */ void Outputdata( int data[], int n ); /* 11 */ void Makedata( int data[], int n ); /* 12 */ int rnd(void); /* 13 */ /* 14 */ /* 15 */ /* 16 */ main() /* 17 */ { /* 18 */ int data[MaxNumber], i; /* 19 */ /* 20 */ Makedata(data, MaxNumber); /* 21 */ ShellSort(data, MaxNumber); /* 22 */ Outputdata(data, MaxNumber); /* 23 */ } /* 24 */ /* 25 */ void ShellSort(int data[], int n) /* 26 */ { /* 27 */ int i, skip; /* 28 */ /* 29 */ skip = n / 2; /* 30 */ while( skip > 0 ) /* 31 */ { /* 32 */ SimpleInsertion( data, skip, n ); /* 33 */ skip = skip / 2; /* 34 */ } /* 35 */ } /* 36 */ /* 37 */ void SimpleInsertion(int data[], int skip, int n) /* 38 */ { /* 39 */ int tmp, i, j; /* 40 */ /* 41 */ for (i=skip; i < n; i=i+skip) /* 42 */ for (j=i-skip; j >= 0; j=j-skip) /* 43 */ if(data[j] > data[j+skip]) /* 44 */ { /* 45 */ tmp = data[j]; /* 46 */ data[j] = data[j+skip]; /* 47 */ data[j+skip] = tmp; /* 48 */ } /* 49 */ } /* 50 */ /* 51 */ void Outputdata(int data[], int n) /* 52 */ { /* 53 */ int i; /* 54 */ /* 55 */ for (i=0; i < n; i++) /* 56 */ { /* 57 */ printf("%8d", data[i]); /* 58 */ } /* 59 */ } /* 60 */ /* 61 */ void Makedata( int data[], int n) /* 62 */ { /* 63 */ int i; /* 64 */ /* 65 */ for (i=0; i < n; i++) /* 66 */ data[i] = rnd(); /* 67 */ } /* 68 */ /* 69 */ int rnd(void) /* 70 */ { /* 71 */ static unsigned long mod = INIT; /* 72 */ /* 73 */ mod = (23 * mod) % 32749; /* 74 */ return mod; /* 75 */ }
37〜49は、単純挿入法の関数である。プログラム6−3で紹介した関数と別なものをここでは紹介した。一見バブルソートに外観が似ているが、基本的な考え方は単純挿入法であることに注意しよう。ただし、変数skipを用いて1次元的なデータをskip個おきに取っていくことによって、ブロックに分割しているように扱っている。 25〜35では、分割の幅をデータの個数の半分を初期値として、幅が1になる値を1/2にして単純挿入法を繰り返している。上記シェルソートでは、分割の幅を1/2にして求めているが、任意でよいが、なるべく互いに素(割り切れない)の数を選ぶとよい。この幅の取り方によってデータの入れ替え回数が変わることが知られている。
D.E.Knuthは、以下のような数列で分割の幅を採用すると効率がよいことを示した。
1、4、13、40、121、..
一般的に、Si+1 = 3*Si +1, S1=1 で得られる数列を逆順にとるものとする。これらの数値は、互いに素ではないが、より効率的であることが知られている。プログラム6−5−2は、上記Knuthが推奨する数列で得られた数値を分割幅に採用した例である。
プログラム6−6−2
/* 1 */ /* Program 6-6-2 */ /* 2 */ /* Shell Sort( Knuth Version ) */ /* 3 */ /* 4 */ #include<stdio.h> /* 5 */ #define MaxNumber 100 /* 6 */ #define INIT 1984 /* 7 */ /* 8 */ void ShellSort(int data[], int n); /* 9 */ void SimpleInsertion( int data[], int skip, int n ); /* 10 */ void Outputdata( int data[], int n ); /* 11 */ void Makedata( int data[], int n ); /* 12 */ int rnd(void); /* 13 */ /* 14 */ /* 15 */ /* 16 */ main() /* 17 */ { /* 18 */ int data[MaxNumber], i; /* 19 */ /* 20 */ Makedata(data, MaxNumber); /* 21 */ ShellSort(data, MaxNumber); /* 22 */ Outputdata(data, MaxNumber); /* 23 */ } /* 24 */ /* 25 */ void ShellSort(int data[], int n) /* 26 */ { /* 27 */ int i, skip[] = {121,40,13,4,1}; /* 28 */ /* 29 */ for ( i=0; i < 5; i++ ) /* 30 */ SimpleInsertion( data, skip[i], n ); /* 31 */ } /* 32 */ /* 33 */ void SimpleInsertion(int data[], int skip, int n) /* 34 */ { /* 35 */ int tmp, i, j; /* 36 */ /* 37 */ for (i=skip; i < n; i=i+skip) /* 38 */ for (j=i-skip; j >= 0; j=j-skip) /* 39 */ if(data[j] > data[j+skip]) /* 40 */ { /* 41 */ tmp = data[j]; /* 42 */ data[j] = data[j+skip]; /* 43 */ data[j+skip] = tmp; /* 44 */ } /* 45 */ } /* 46 */ /* 47 */ void Outputdata(int data[], int n) /* 48 */ { /* 49 */ int i; /* 50 */ /* 51 */ for (i=0; i < n; i++) /* 52 */ { /* 53 */ printf("%8d", data[i]); /* 54 */ } /* 55 */ } /* 56 */ /* 57 */ void Makedata( int data[], int n) /* 58 */ { /* 59 */ int i; /* 60 */ /* 61 */ for (i=0; i < n; i++) /* 62 */ data[i] = rnd(); /* 63 */ } /* 64 */ /* 65 */ int rnd(void) /* 66 */ { /* 67 */ static unsigned long mod = INIT; /* 68 */ /* 69 */ mod = (23 * mod) % 32749; /* 70 */ return mod; /* 71 */ }
シェルソートの計算時間量は、分割の幅の取り方によりO(n^1.2)からO(n^2)であることが、知られている。証明については、難しいため省略する。さらに、単純挿入法の関数をプログラム6−3で紹介したものと置き換えた例を以下に示そう。
プログラム6−6−3
/* 1 */ /* Program 6-6-3 */ /* 2 */ /* Shell Sort */ /* 3 */ /* 4 */ #include<stdio.h> /* 5 */ #define MaxNumber 200 /* 6 */ #define INIT 1984 /* 7 */ /* 8 */ void ShellSort(int data[], int n); /* 9 */ void SimpleInsertion2( int data[], int skip, int n ); /* 10 */ void Outputdata( int data[], int n ); /* 11 */ void Makedata( int data[], int n ); /* 12 */ int rnd(void); /* 13 */ /* 14 */ /* 15 */ /* 16 */ main() /* 17 */ { /* 18 */ int data[MaxNumber], i; /* 19 */ /* 20 */ Makedata(data, MaxNumber); /* 21 */ ShellSort(data, MaxNumber); /* 22 */ Outputdata(data, MaxNumber); /* 23 */ } /* 24 */ /* 25 */ void ShellSort(int data[], int n) /* 26 */ { /* 27 */ int i, skip[] = {121,40,13,4,1}; /* 28 */ /* 29 */ for ( i=0; i < 5; i++ ) /* 30 */ SimpleInsertion2( data, skip[i], n ); /* 31 */ } /* 32 */ /* 33 */ void SimpleInsertion2(int data[], int skip, int n) /* 34 */ { /* 35 */ int tmp, i, j; /* 36 */ /* 37 */ for( j=skip; j < n; j++ ) /* 38 */ { /* 39 */ i = j - skip; /* 40 */ tmp = data[j]; /* 41 */ while( (i>=0) && (tmp<data[i]) ) /* 42 */ { /* 43 */ data[i+skip] = data[i]; /* 44 */ i = i - skip; /* 45 */ } /* 46 */ data[i+skip] = tmp; /* 47 */ } /* 48 */ } /* 49 */ /* 50 */ void Outputdata(int data[], int n) /* 51 */ { /* 52 */ int i; /* 53 */ /* 54 */ for (i=0; i < n; i++) /* 55 */ { /* 56 */ printf("%8d", data[i]); /* 57 */ } /* 58 */ } /* 59 */ /* 60 */ void Makedata( int data[], int n) /* 61 */ { /* 62 */ int i; /* 63 */ /* 64 */ for (i=0; i < n; i++) /* 65 */ data[i] = rnd(); /* 66 */ } /* 67 */ /* 68 */ int rnd(void) /* 69 */ { /* 70 */ static unsigned long mod = INIT; /* 71 */ /* 72 */ mod = (23 * mod) % 32749; /* 73 */ return mod; /* 74 */ }練習問題
-
分割幅の違いによるデータの入れ替え回数の違いを、実際にカウンターをプログラム内に埋め込んで、確かめてみよう。
分割幅は、以下の3つの場合について行なう。
(1) 分割を行なわず、初めから skip=1として行なう。
カウンタは、グローバルに変数宣言し、例えばプログラム6−5についていえば、
(2) skip=2/n,4/n,8/n,...1の順で分割を行なう。
(3) skip=...,121,40,13,4,1の順で行なう。
/* 37 */ void SimpleInsertion(int data[], int skip, int n) /* 38 */ { /* 39 */ int tmp, i, j; /* 40 */ /* 41 */ for (i=skip; i < n; i=i+skip) /* 42 */ for (j=i-skip; j >= 0; j=j-skip) /* 43 */ if(data[j] > data[j+skip]) /* 44 */ { /* 45 */ tmp = data[j]; /* 46 */ data[j] = data[j+skip]; /* 47 */ data[j+skip] = tmp; count = count + 3; /* 48 */ } /* 49 */ } /* 50 */のように、47と48の間にデータの入れ替え回数を計算する命令を挿入してやればよい。ただし初期値として count=0 がセットされていなければならない。 (4) マージソート
-
マージソートの基本的な考え方は、あらかじめ並べ替えが完了している2つのデータを1つに合併する操作を組織的に適用することによって、最終的にソートされたデータを得るものである。本来は、磁気テープによる外部ソートを行なう有力な方法として発達してきたが、ここでは内部ソートとして考えてみよう。以下簡単のため、データの個数を2のべき乗と仮定する。基本原理(マージ操作)を例によって示す。2本のソート済みの磁気テープが存在しているとする。
13 43 45 56 ← テープ1 7 18 68 95 ← テープ2
これらを、マージしよう。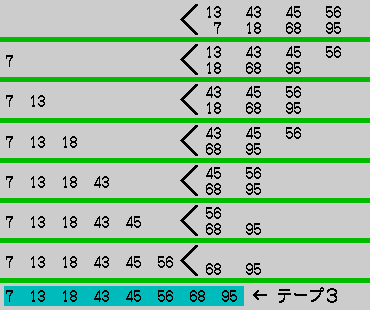
この場合、磁気テープを余分に1本必要とすることに注意。
上記基本原理を、1次元配列のデータに対して行なうために、データを2分割し、疑似的に2本の磁気テープを構成する。例を用いて、(内部的な)マージソートの動作を示そう。
マージソートのプログラムを以下に示す。入力データ n=2^3個とする。 45 56 43 13 95 18 7 68
ステップ1 上記データを2つに分割する。 ( 45 56 43 13 ) と ( 95 18 7 68 ) の2組のデータに分ける。 2組の各データをさらに分割する。 ( 45 56 ) と ( 43 13 ) と ( 95 18 ) と ( 7 68 ) 上記操作を2つのデータの組になるまで、繰り返す。
ステップ2 2つのデータの各組に対し、マージ操作を行なう。よって、 ( 45 56 ) と ( 13 43 ) と ( 18 95 ) と ( 7 68 ) さらに、マージ操作を繰り返す。よって ( 13 43 45 56 ) と ( 7 18 68 95 ) となる。さらに、マージ操作を行なう。よって、 7 13 18 43 45 56 68 95 となる。
プログラム6−7
/* 1 */ /* Program 6-7 */ /* 2 */ /* Merge Sort */ /* 3 */ /* 4 */ #include<stdio.h> /* 5 */ #define MaxNumber 128 /* 6 */ #define INIT 1984 /* 7 */ /* 8 */ void MergeSort( int data[], int top, int bottom ); /* 9 */ void Merge( int data[], int l, int m ); /* 10 */ void Outputdata( int data[], int n ); /* 11 */ void Makedata( int data[], int n ); /* 12 */ int rnd(void); /* 13 */ /* 14 */ /* 15 */ /* 16 */ main() /* 17 */ { /* 18 */ int data[MaxNumber+1], i; /* 19 */ /* 20 */ Makedata(data, MaxNumber); /* 21 */ MergeSort(data, 1, MaxNumber); /* 22 */ Outputdata(data, MaxNumber); /* 23 */ } /* 24 */ /* 25 */ void MergeSort( int data[], int left, int right ) /* 26 */ { /* 27 */ int mid; /* 28 */ /* 29 */ if( left < right ) /* 30 */ { /* 31 */ mid = (right - left + 1) / 2; /* 32 */ MergeSort( data, left, left+mid-1 ); /* 33 */ MergeSort( data, left+mid, right ); /* 34 */ Merge( data, left, left+mid ); /* 35 */ } /* 36 */ } /* 37 */ /* 38 */ void Merge( int data[], int l, int m ) /* 39 */ { /* 40 */ int tmp[MaxNumber+1], h, i, j, k, r; /* 41 */ /* 42 */ i = l; /* 43 */ j = m; /* 44 */ r = 2*m-l; /* 45 */ k = l; /* 46 */ while( (i<m) && (j<r) ) /* 47 */ { /* 48 */ if( data[i]<data[j] ) /* 49 */ { /* 50 */ tmp[k] = data[i]; /* 51 */ i++; /* 52 */ } /* 53 */ else /* 54 */ { /* 55 */ tmp[k] = data[j]; /* 56 */ j++; /* 57 */ } /* 58 */ k++; /* 59 */ } /* 60 */ if( i<m ) /* 61 */ for( h=i; h<m; h++ ) /* 62 */ { /* 63 */ tmp[k] = data[h]; /* 64 */ k++; /* 65 */ } /* 66 */ if( j<r ) /* 67 */ for( h=j; h<r; h++ ) /* 68 */ { /* 69 */ tmp[k] = data[h]; /* 70 */ k++; /* 71 */ } /* 72 */ for( h=l; h<r; h++ ) /* 73 */ data[h] = tmp[h]; /* 74 */ } /* 75 */ /* 76 */ void Outputdata(int data[], int n) /* 77 */ { /* 78 */ int i; /* 79 */ /* 80 */ for (i=1; i <= n; i++) /* 81 */ { /* 82 */ printf("%8d", data[i]); /* 83 */ } /* 84 */ printf("\n"); /* 85 */ } /* 86 */ /* 87 */ void Makedata( int data[], int n) /* 88 */ { /* 89 */ int i; /* 90 */ /* 91 */ for (i=1; i <= n; i++) /* 92 */ data[i] = rnd(); /* 93 */ } /* 94 */ /* 95 */ int rnd(void) /* 96 */ { /* 97 */ static unsigned long mod = INIT; /* 98 */ /* 99 */ mod = (23 * mod) % 32749; /* 100 */ return mod; /* 101 */ }
マージソートの計算時間量は、n*log(n)である。データが2個になるまでデータの2分割を繰り返していく。この分割は、log(n)回行なわれる。各ステージでは、並べ替えが行なわれ、その計算量はO(n)である。よって、全体でn*log(n)となる。
演習問題
- 関数MergeSort内で再帰的にMergeSortを呼んでいる。大量のデータを処理したり再帰のもぐる段階が増すと、再帰的な関数は一般的に効率が悪い。そこで、再帰を用いないでMergeSortプログロムを書き換えよ。
-
シェルソートは、分割法を適用したひとつの方法である。基本的な考え方は、与えられたデータをいくつかのブロックに分割し、そのブロックに対し単純挿入法を行なうもである。データをいくつかのブロックに分割し大ざっぱな並べ替えを繰り返しながら、最終的には全データに対して並べ替えをする。このように分割することによって、データの入れ替えの回数を少なくすることを、D.Shellによって考えられ、シェルソートの名前が付いた。
例を用いて、シェルソートの動作を示そう。
| 入力データ |
45 56 13 43 95 18 7 68 |
| ステップ1 |
分割の幅をskip=4とし、上記データをいくつかのブロックに分割する。 45 56 13 43 95 18 7 68 ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ B1 B2 B3 B4 B1 B2 B3 B4 ←便宜上ブロックに名前を付けた このブロック内で並べ替えをおこなう。 B1ブロック 45 95 → 45 95 B2ブロック 56 18 → 18 56 B3ブロック 13 7 → 7 13 B4ブロック 43 68 → 43 68 よって、 45 18 7 43 95 56 13 68 となる。 |
| ステップ2 |
分割の幅を1/2にする。skip=2としてブロックに分割する。
45 18 7 43 95 56 13 68
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
B1 B2 B1 B2 B1 B2 B1 B2
このブロック内で並べ替えを行なう。
B1ブロック 45 7 95 13 → 7 13 45 95
B2ブロック 18 43 56 68 → 18 43 56 68
よって、
7 18 13 43 45 56 95 68
となる。
|
| ステップ3 |
分割の幅をさらに1/2にする。skip=1となり、全データを一つのブロックとして考える。よって、
7 13 18 43 45 56 68 95となり、並べ替えが完了する。
|
シェルソートのプログラムを以下に示そう。
6.4 効率のよいソートプログラムとは?
そこで、データの大きさと計算時間との関係を知ることは、重要なことである。さらに、扱うデータの個数や用途により、採用するアルゴリズムを交えることも必要である。
No.17の最後に提示した上級演習問題を、No.17−19で示したすべてのプログラムについて行なってみることをすすめる。そして、実行スピードの限界となるデータの個数を断定せよ。