** 補足説明 **
その前に,メモリについて復習しておく.
そもそも,コンピュータはメモリ内の数値,演算子をメモリに書いておき,それを適宜レジスタと呼ばれるCPU内の計算用メモリにコピーして計算を行う.コピーする時,”どこそこにある数値”などと指定してコピーを行う.この”どこそこ”を表しているのがメモリの番地である.
また,メモリとは1byte単位に区切られた連続した空間である.各byteには名前ならぬ番地が(小さい順に,順番に)ついている.逆に見ればメモリ空間内には番地がついていて,そこに1byte分の領域が割り当てられている.
番地と言う言葉が出てきたが,これは日常生活で我々が土地を適当な大きさに切り分け,番地付けをする時の番地と同じ事である(例えば5-2-35というのは5丁目2番地の35を表すように).つまり我々は,広大な荒れ地(メモリ空間全部)を適当な大きさ(1byte)に切り分け,番地付けを行って処理しているのである.1byteに区切られた領域に整数や文字コードなどを格納しておくことが出来る.
ここで,以後の説明のために用語の解説をしておく.
また,アドレスと変数名を同意義で使う箇所があるが,実際は異なるものであることに注意していただきたい. |
マシン語やアセンブラでプログラムを作成していた頃は,このアドレスを直接プログラマが指定しなければならなかった.今で言う変数名がないだけでなく,どこのアドレス空間が空いているか常に気にしながらプログラムを組まなければならなかった.これは非常に面倒な作業で,更にサブルーチンを組み合せる時などは,”アドレスがいくつずれるか”や”アドレスが重複していないか”などを心配する必要があった.
今,我々が通常用いる言語ではこのような心配はない.先駆者達が苦労の末,”コンパイラ”という便利なものを開発してくれたからである.
コンパイラは,変数名を適当なアドレスに割り付け,その管理を行う.コンパイラは,我々が書いたプログラム(ソースプログラム)をマシン語(あるいはOSが理解できる言語)に変換する過程で,変数名を全てアドレスに直して扱う.
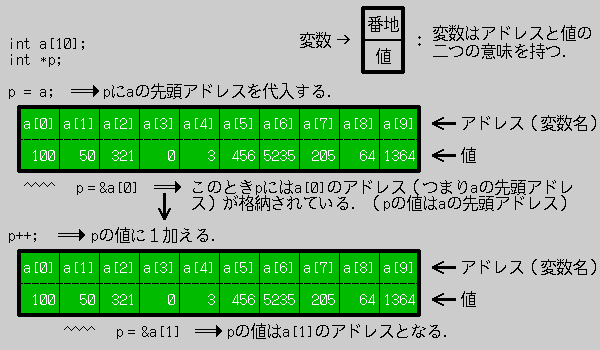
ここで変数名と言うものが出てきたが,これはchar a,int bなどのa,b のことである.我々が通常”変数”と呼んで扱っているのはこの変数名である.これまでの説明で,変数名は格納するアドレスを意味していることお分かりいただけるだろう.変数にはもう一つの側面があり,それは格納されている値である(3.2節参照).この概念は,この後の解説で非常に大切なので,覚えておいていただきたい.(図−1参)
ex1.

各変数は,変数名と値を持つ.例えば,変数名iに対して,その値はint型の4である.
では,図−1で記されている残りの単語 intとか charは何を意味するのであろうか.
これは,格納される値の性質(プログラム言語では型と呼ばれる)を記述している.性質と言っても,早い話が”格納される値は1wordで納まる範囲か否か”という事が重要なことである(それだけではない).1wordの大きさはコンピュータ(CPU)によって異なるが,ここでは16bitsと仮定して話を進める.16bitsということは,(コンピュータ内部では2進数で扱うので)2の16乗=65536でこの大きさを越える値を保持することは出来ない.また,負の数も扱うとなると,この限界値は32768となって,更に小さくなる.しかし,我々が実際にコンピュータに処理させたい作業に,この様な制限はない.国家予算一つをとっても軽くこの値を越えてしまう.更に,数値だけでなく文字列や,音声,静止画,動画も処理させたい.
ここでは,大きな数値,文字列に限って説明する.画像,音声なども本質的には変りないのだが,具体的にCの構文で説明出来るものに限ることにする.(画像,音声の処理については巻末(付録1)参照)
ところで,物の本によっては変数を説明する時に,箱に例えて説明する本がある(この講座ではお皿を用いた).つまり変数とは箱であり,変数名とはその箱の名前で,その容積(中に入れることが出来る大きさ)は決っている,とする.それでは,この考えを取り入れたとして,もし我々の日常生活で箱がいっぱいになったらどうするか.
1)同じ大きさの箱を沢山,用意する.現実世界では,2)の様に中に入れたいものにあわせて箱を適宜用意するのが理想的であろう.しかし,メモリ空間内の箱(変数)の大きさは決っている.1wordの壁は破れないのだ.仮に1wordの大きさを変更しても,その大きさを越えることは出来ない.(例えば1wordを32bitsに設定しても,2の32乗=4294967296を越えることは出来ない.これは単なる一時しのぎに過ぎない)
2)もっと大きな箱(容積の大きい箱)を用意する.
逆に,予測し得る大きさの箱を用意しておくことは,メモリの無駄になる.なぜなら,1wordに大きな空間を与えると,使えるアドレスの数が減少する.(広大な土地を大きく切り分けて分譲すると,分譲地を購入できる人数は減ってしまう) さらに,この様な巨大な空間がごろごろあっても,その中身を一杯にすることは滅多にない.(図−2参)
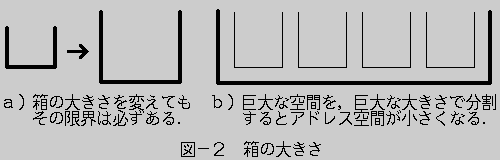
我々は,予測し得ない大きさの,数値も扱わせたいし文字列も処理させたい.しかし,1wordの大きさを,これ以上大きくすることは出来ない.
そして,もうひとつ.メモリ空間は連続していると言うことも忘れてはならない.これは長い文字列を扱うときなど便利である.箱を二つ連続して用意させれば,1word以上の大きさ(長さ)の文字列をそのまま連続して格納することが出来る.
結局,我々は消極的にも積極的にも,1)の方法をとらざるを得ない.
しかし,これは非常にシンプルで良い方法なのである.なぜなら現実の世界と違って,ソフトウェア上の荷物(データ)は(現実世界でどんなに巨大であろうと)分割して格納することが出来るからである.例えば100桁の加減算を行わせたければ,変数を100個用意して,(一つの箱には一桁しか入らないと仮定する)計算させることが出来る.先走った話だが,変数を100個用意するのに,変数名を100個考えることはない.配列という,親戚を集めて同じ名字を名乗らせる方法があるからである.
ようやくこれで,配列とポインタに至る準備が出来た.
今まで我々は,一つの変数を一つのアドレスとして操作してきたが,変数の限界値(箱の大きさ)を越えた処理をさせたいときに,一つではなく複数にわたってデータを格納させたい.しかもデータエリアは連続して確保できるので,入りきらない様なら”次の箱”に入れることが出来るはずであり,実際そうなっている.
ところが,このように”複数の変数にわたるデータ”を格納しようとした場合,”いくつ変数(箱)を使うのか”という事が問題になる.つまり,”データの大きさはどれくらいか”と言うことである.これに関しても我々は二つの解答を用意できる.
1)は予め箱を多く用意しておこうというものである.
1) 処理するのに十分な個数を予め用意して処理させる. 2) 実行中に,データの大きさが分かったところで,その大きさに見合う分の個数を用意する.
これに対して2)は必要な箱の数が分かったら,その数だけ箱を用意しようと言うものである.
もうお気付きであろうが,1)の考え方に基づくデータ構造が配列であり,2)の考え方に基づくデータ構造がポインタである.(必要な個数が分かってから箱を用意する方法については,後日述べることにする)
さて,ここで先ほどの”変数は値と名前(アドレス)を持つ”と言うことを思い出していただきたい.通常,どの言語でも変数は各データ型にあったデータを値として持つが,Cでは(以下の話は全てCに限る)ポインタ変数は値としてそのデータ型のデータエリアのアドレスを持つ.配列も同じである.
ex2.
| int a; | → | 変数aはint型の値を格納する変数である. |
| int *pi1, *pi2; | → | 変数pi1,pi2はint型の値を格納する変数のアドレスを格納することが出来る. |
| int hi[100]; | → | 変数hiはint型のデータを連続して100個格納できるデータエリアのアドレスを格納する. |
| pi1 = &a; | → | pi1は定義によりaのアドレスを持つ事が出来る.(&はその変数のアドレスを算出する演算子) |
| pi2 = hi; | → | pi2はint型のデータを格納するデータエリアのアドレスを格納することが出来るので,この様な記述が出来る.意味としては pi2 = &hi[0]; と同じである. |
| pi1 = &hi[50]; | → | 同じくpi1はint型の値を格納する変数のアドレスを格納出来るので,この様な記述が出来る. |
*注意
- int型のデータ(値)が決して整数全体を表わしているのではないことに注意!! 整数とは無限にあり,int型の値とは最大値(最小値)がコンパイラによって決められている. また,hiは空間の大きさ(100)を明示しているが,pi1,pi2は明示していない.
つまり配列はhiがその先頭アドレスを格納していて,添字([ ]内の数字)が(先頭アドレスより)何番目の値であるかを表す.
これがポインタと配列が同じであると言うことである.つまりCでは,配列とは便宜上”何番目の値”というのを添字によって簡単に表しているに過ぎない.実際コンパイラの内部処理(コード生成)では配列表記([ ]など)を全てポインタ表記(*や&)に直してしまう.
ex3.
pi1 = &hi[50]; → pi1 = hi + 50;
hi[6] = 'k'; → *(hi + 6) = 'k';
逆にポインタ変数として宣言したものに[ ]をつけて簡単に途中のデータだけを操作することも出来る.(実際,私(zoh')の組んだプログラムはいくつかそうなっている)
ex4.
printf("%d\n", pi1[7]);
*注意
- ただし,この場合は,明らかにpi1に対して領域を与えていなければならない.
つまり,pi1は必ずどこかの(大きさ7以上の)エリアのアドレスを格納していなければならない.
ただし,配列宣言したものをポインタ変数と同じ様に扱うには,いくつか制限がある.これについては後述する.先ほど,”配列という,親戚を集めて同じ名字を名乗らせる方法”と述べたが,つまりこれはポインタにしろ,配列にしろ,(ある時点では)あるデータエリアのアドレスが(値として)格納されている,ということによる.その変数名からは,格納している具体的なアドレスは分からないが,必ずそのエリア内にあるアドレスを格納している(つまり本当の物理的アドレスは分からないが,どこかの領域を表している).という事は逆に,その領域全体を総して,その変数名で呼んでも構わない.(図−3参)
ex5.

すでに述べたように変数はアドレスと格納内容を意味する.(以下,アドレスの参照について解説する.) 配列変数aの具体的な位置は,[ ]内の数字で表される.つまりaが名字,[ ]の添字が名前に相当する.これは名字は一族を総称し,名前は具体的な個人名を表す,という構図に似ている.
この考え方は,少々混乱を招くかも知れない.すでに述べたように,配列名にはその先頭アドレスが格納されており,添え字はその数字分だけ後ろのアドレスを指す.この考え方に従えば,aにはa[0]のアドレスが格納されていることになる.領域全体と,変数一つでは大きく異なるように見える.しかし,両者は同じ事を言っているのである.
もう少し詳しく解説しよう.(図−4参)
ex6.
 図−4 配列2 |
ポインタ変数に演算を行なうことによって格納されるアドレスが変わる.しかし,その領域の一部を表すことに変りはない.(図のマスの中の値は変らない)
ex6.でpもaもどこかの領域を表していることにかわりないことが,お分かりいただけるであろう.つまり,ポインタ変数(配列名)が格納できるデータエリアのアドレスを全て表わすと見なせば,図−3のようなことが言える.
さて,ポインタと配列のまとめとして,以下の二つの違いを明らかにしてみよう.(PL13参)
1) int a[100];1)はint型のデータを100個格納できるエリアを確保し,aのアドレスは確保したエリアの先頭アドレスとなる.
2) int *b;
これに対して2)は単にbはint型のデータが格納される領域のアドレスが代入できること(bは値としてint型のデータエリアのアドレスをとること)しか,明示していない.b自身はどこかのアドレスが割り付けられるが,bが指す領域の確保は行われず,どこのアドレスも入っていない.(単にint b とした場合と比較して,とる値の種類が異なるだけである)
ポインタと配列の大きな違いの一つは,宣言したときに領域を確保しているか否かと言うことである.この例でも1)は領域を確保しているが,2)はしていない.そして,配列に対しては(宣言時に)初期化が出来るが,ポインタ変数では出来ない.唯一の例外は,文字列へのポインタであり,これは宣言時に初期化できる(但し,内容の変更が出来ない).これについては後述する.
これで配列名,ポインタ変数,アドレス,値の関係がお分かり頂けたかと思う.
もし,読み直し,他書を読み,例題プログラムを見,過去の講義内容を見返しても分からないときは,どしどしご質問頂きたい.C言語に限らず新しい言語は豊富なデータ構造を記述する機能が備わっているが,ポインタの概念が非常に重要で,この後の講義では例題として多く扱う.
ここからは今までの(4月からの)解説で,ポインタ(配列),変数名と値に関して重要な部分を解説し,この講義の内容を理解するのに一層役立つであろうと思われることについて述べる.該当するPLを読み直していただくと,より一層理解が深まるであろう.
まず,(C言語で)一番多く関係し,かつ最も身近な例は二つの変数の値を交換する,swap関数である.(PL13プログラム5−5参)
力試しに以下のプログラムをよく見ていただきたい.
ex7.
プログラム1 間違ったswap関数void badswap(int a, int b) /* 二つのint型の値を交換する */
{
int dum;
dum = a;
a = b;
b = dum;
}
|
C言語では,関数に渡した引数(変数の一種)はその値が参照されるに過ぎない(値参照呼びだしという).(図−5参)
ex8.
main()
{
void whoami(int x);
int a;
…………………
a = 3; ← 関数whoamiにaが渡される前の値は3である.
whoami(a);
………………… ← 関数whoamiにから返ってきてもaの値は3である.
}
void whoami(int a)
{
…………………
a +=300;
a *= 37;
…………………
}
図−5 C言語の関数呼出しと引数の値 |
引数として渡された変数の値は,呼ばれた関数の側で何をされても,返ってきたときには渡されたときと同じである.
このことが,先のswap関数の間違いを表わしている.つまり,badswap関数で値を交換しても,呼んだ関数に戻ってしまえば,交換されていないのである.(試されると良い) 値の交換は,非常に良く使うものなので,いちいち書きたくはない.出来れば,このように手続き化しておいて適宜使いたいものである.ではどうするか.
これまでの話しの流れと,PL13によりポインタが解決策であることは明白であるが,その解説にはいる前に,代入について詳しく述べておく.
代入とは,”ある変数の値を,別の値(定数,変数の値)にすること”である.式で書けば簡単で, a = 23; は変数aの値を23にすることを表わしているし, b = a; はbの値をaの値に書き換えることを表わしている.
”何を当たり前のことを”とおっしゃるかも知れないが,ではこの質問はどうか.
”b = a;において,左辺のbと右辺のaは何を表わしているか?”
この質問のヒントは,変数が二つの要素(変数名と値)から成り立っているということである.(変数は二つの意味を持つ)
解答から述べてしまえば,左辺のbは格納する場所(つまりアドレス)を表わしており,右辺のaは格納されている値を表わしている.つまりb = a;はbの格納場所(アドレス)にaの値を入れよ,ということを表わしているのである.代入式において代入される変数が左側にあるのは,このことが(つまり左辺に代入されるということが)その変数のアドレスを参照することを意味しているためであり,右辺に変数だけでなく,式,定数,変数を書くことが出来るのは単に値しか参照しないことを意味するためである.(余談であるが,流れ図やアルゴリズムの抽象的な記述では,代入を<-で表わす.つまりこの例では b<-a となる.これは代入の概念を良く表わしている)
話しが脇道にそれるが,定数も当然,アドレス(格納場所)を持つ.値は固定されており,そのものである.ただし.変数と違ってその具体的なアドレスを探ることは難しい(例えば,&2などとやっても2の格納場所は分からない).
ただし,文字列定数だけは別である.文字列定数は,宣言時の初期化でそのアドレスを格納することが出来る(図−6参).ポインタ変数に対して唯一初期化できるのは,この文字列へのポインタだけである.
ex9.
|
とにかく変数にしろ,定数にしろアドレスと値を持ち,代入において左辺と右辺で示すものが違うことを認識していただければよい.右辺が何を意味するかは,左辺に代入される値の型が示してくれる.(この型が違うとエラーになる)
さて,なぜこのことが先のswap関数の解決策になるのか.
くどいようであるが,呼ばれた関数側では,引き渡された引数の値に対して何をしても,呼び出した関数に戻ってきたときにはその値は変わっていない.しかし,その値が他の変数(定数)のアドレスを格納しているとするとどうなるか.答えから見てしまおう.
ex10.
プログラム2 正しいswap関数void goodswap(int *a, int *b) /* 二つのint型の値を交換する */
{
int dum;
dum = *a;
*a = *b;
*b = dum;
}
|
つまり,関数に対して直接渡された値(引数)は,いじっても(戻ってしまえば)関係ないが,それがアドレスの場合,その格納場所にある値は操作して変えてしまうことができる.
通常の代入を考えると,このことは一層分かりやすくなる.
通常の代入は,代入された物をいじっても代入したものには影響がない.しかし,アドレスを代入して,そのアドレスの指す中身(格納してある値)をいじると代入した方の中身もかわる.(図−7参)
ex11.
int a, b;
b = 5;
a = b;
a += 2; → bの値は5のままである.
---- a)通常の変数の代入 ----
int *a, b[ ] = {9, 8, 7, 6, 5, 4, 3, 2, 1};
a = b;
*a = 1; → b[0]の値が1になる.
---- b)ポインタ変数の代入 ----
図−7 値とアドレスの代入の違い中身をいじると,その違いが現れる. |
理解をさらに深めるために,badswap関数とgoodswap関数,そして以下のプログラムを実際に動かしてみて,引数の値が呼び出される前と後でどう変わるか調べてみると良い.(swap関数のmain関数についてはPL13参)
ex12.
#include <stdio.h>
main()
{
int n, p;
scanf("\d", &n);
p = oneofpower(n);
printf("%d! = %d\n", n, p);
}
=> 実行例
int oneofpower(int a) /* 階乗関数 */ 5
{ 5! = 120
int ret;
ret = 1;
while(a > 0)
ret = ret * a--;
return ret;
}
プログラム3 階乗関数oneofpower関数側で引数のaを操作しても,main関数では変わっていない. |
関数の定義部の引数がポインタであったら,呼び出す側は変数のアドレスを渡す(これは再三述べたし,ポインタ型の意味からも当たり前である).しかし,アドレスを渡すからといって何でもかんでも変数に&を付ければいいわけではない.例えばプログラム5−10−4のswapchar関数に対して,呼びだし側は&演算子を用いずに渡している.これはその変数(st,dum)がポインタ型なので,最初から値としてアドレスを持っているためである.このことは渡す関数の引数の型と,渡される関数の引数の型を注意しなければならないということを指摘している.
ところで,引数として変数のアドレスを渡す関数で,我々がすでに良く使っている関数がある.scanf関数である.例えば上のプログラム3のmain関数でも scanf("%d", &n); として呼び出している.なぜアドレスを渡すのかということは,swap関数と同じ理由による.つまり,scanf("%d", n) としてしまうと,nには値が入らない(実際には最近のコンパイラはwarningを出す).scanf関数は引数としてポインタ変数の値,つまりアドレスをとるのである.
今回の講義(前半)の例題プログラム5−10を見ていただきたい.scanf関数の呼びだし方を見ると,先のポインタ変数の値と配列名の値が同じであるということがお分かり頂けるであろう.配列で宣言しておいてその先頭アドレスをscanf関数に渡しているのである.(図−8参)
ex13.
char astring[80];
…………………
scanf("%s", astring); ← 配列名astringにはその領域の先頭アドレスが入っている.
…………………
図−8 配列名はアドレスを値として持つ. |
この他に注意すべきものとしては,出力フォーマット"%s"がある.出力フォーマット"%s"は,その引数として(文字列を格納している格納場所の)アドレスをとることを指定する.(図−9参)
ex14.
char astring[20];
scanf("%s", astring);
printf("Input string is %s.\n", astring); <= astringは先頭アドレスを
格納している.
---- a)文字列を出力.----
char otherstring[20];
int i, l;
scanf("%s", otherstring);
l = strlen(otherstring);
printf("Input string is ");
for (i = 0; i < l; i++)
printf("%c", otherstring[i]); <= otherstring[i]は各文字を格納
printf("\n"); している.
---- b)文字を順番に出力.----
図−9 文字の出力どちらも同じ結果になる. |
これらは,本文の趣旨には関係ないので今まで解説しなかったが,それぞれ重要なことなので,理解していただきたい.
まず,ポインタと配列の大きな違いである.これについては,もっと前に解説すべきであったが,代入の概念が必要であったので,ここに来てしまった.
最初の違いは,領域を確保しているか否か,という事であった.次の違いは宣言時に代入(初期化)出来るかと言うことであった(ただし,文字列定数は初期化のために代入文が書ける).いくつか宣言時の初期化の例を示そう.(図−9参)
ex15.
1)char a[ ] = "Dog.";
→ この書き方が出来るのは宣言時だけである.Cでは文字列の代入は出来な
い事に注意.配列の大きさは,自動的に5になる.
+----+----+----+----+----+
|a[0]|a[1]|a[2]|a[3]|a[4]| ← アドレス(変数名)
+----+----+----+----+----+
| D| o| g| .| \0| ← 値
+----+----+----+----+----+
2)char b[ ] = {'D', 'o', 'g', '.', '\0'};
→ これが正式な配列での初期化.通常の配列ではこのように初期化する.
この例では,最後に \0 が入っていることに注意.これがないと配列の大
きさが決らない.簡略図は,1)のa[x]がb[x]になるだけである.大きさ
は同じく自動的に5になる.
3)char *c = "Cat.";
+----+ +----+----+----+----+----+
| c| |1000|1008|1016|1024|1032| ← アドレス
+----+ +----+----+----+----+----+
|1000| | C| a| t| .| \0| ← 値
+----+ +----+----+----+----+----+
→ cにはCat.という文字列の先頭アドレスが入っている.文字列の最後に自動
的に\0がつくことに注意.
4)char *c = {'C', 'a', 't', '.', '\0'};
→ これは出来ない.コンパイルエラーになる.
図−10 宣言時の初期化1)と3)の違いはPL13の最後でも述べた. |
普通,(あらゆる型の)配列変数の初期化は図−10の2)の様にして行う.文字列のみ,特殊な書き方が許される.
しかし,最大の違いは配列名には代入がでないと言うことである.(図−11参)
ex16.
1)char a[] = "Possible!!"; → これは可能.aの大きさは11.
2)char *p;
char *a = "O.K??";
p = a; → これも可能.pの値はaの先頭アドレスとなる.
3)char q[] = "O.K???";
char b[10];
b = q; → これは不可能.(コンパイルエラー)
4)char p[] = "Possible.";
printf("%s", p + 3); → これは可能.実行結果は sible!!
5)char r[] = "Impossible!!";
r++; → これは不可能.(コンパイルエラー)
図−11 配列名への代入は出来ない. |
しかし配列名に代入は不可能である.図−11の5)は一見正しいように見えるが,r = r + 1;と書き直すと間違いであることに気付くであろう.左辺に配列名を持ってくることは出来ないのだ.ただし,図−11の4)の様に加減算は出来る.
蛇足的なことであるが,関数内で宣言された配列名に対しては代入が出来ないが,関数の引数であれば,その関数内では代入が可能である.(図−12参)
ex17.
int a[] = {9, 8, 7, 6, 5, 4, 3, 2, 1}; → この配列の大きさは9;
…………………
somethig(a);
………………… → この関数内では,a++;という記述は出来ない.
anythig(a);
…………………
void somethig(int *p)
{
…………………
p++; → この結果,次のアドレスになる.
…………………
}
void anythig(int q[])
{
…………………
q++; → これは可能である.
………………… この結果,次のアドレスになる.
}
図−12 関数の引数として宣言されているところでは,代入が出来る.配列名をポインタ型の引数として関数に渡すことは可能である. |
例えば,ex17.のvoid anything(int q[50])とは記述しない.一般に引数が配列であるということさえ分かればよいので,その大きさは記述しない.してもよいが,無視されてしまい意味がない.その証拠に,void anything(int q[50])としても,大きさが50以上の配列を引数として渡しても50未満の配列を渡しても,その型がint型でありさえすれば何のエラーもなしにきちんと動く.
代入は,ともすれば間違えそうであるが,一番の回避方法は,ポインタ型変数はその表記にしたがって,加減算,代入を行い,配列名はその名前そのものか,添字をつけて扱っうという事である.
では,ポインタ変数に対する演算であるが,"++"(一つ進める),"--"(一つ戻す)以外は使わないようにする方が良い.コンパイラが直してしまうからといってex3.で出てきたような *(hi + 50) などという書き方はお勧めしない.
なぜか.理由は二つあげられる.
1)見た目が美しくない.1)は,相対的な位置が分かっているならば,配列表記を用いて hi[50] とした方が見た目が美しいという,少々わがままな見解である.しかし,見た目の良さは,余計なバグを出さずにすむので,あながち的外れな意見でもないであろう.
(一見しただけではポインタを50進めることが読みとりにくい)2)間違った演算が出来てしまう.
2)についてはもっと緊迫した問題をはらむ.これは,C言語の欠点でもあり,しかしそれに対する制御機能がないためにシンプルに仕上がったという利点でもある.
ex2.を用いて解説すると,hiはint型のデータを100個格納できる領域の先頭アドレスを持っているが,このアドレスに対して hi + 200 や hi -5 などという演算が出来てしまう.これは実際コンパイル,実行可能で,その場合の動作は不定である(warningやerrorは出ない).コンパイラは構文上の誤りは検出できるが,内在する意味的な誤りについては検出できない.では,なぜ"++"演算子や"--"演算子はいいのか.当然,char *t = "I wrote." と宣言した直後に,t--; という文は書ける.しかし,実際そんな文を書くプログラマはいないであろう."++"演算子や"--"演算子は,プログラマが注意深く制御できる演算子である.実際,この講義の例題プログラムのポインタ版は,その操作に"++"演算子と"--"演算子を用いる際,その領域内にあることや,その値を気にしながら実行している.プログラマが注意している限り,領域をはみ出すことはない.
といっても領域を越える"++"演算は行なえるし,先の hi に対して hi[200] という操作も行なえるので,注意していただきたい.くどいようであるが,そのような場合はエラー等がでず,実行結果は不定である.
このようにアドレス空間を気にしながらプログラムを組むのは,時代に逆行しているようであるが,(マシン語,アセンブラ時代の話しを思い出そう)それ故に言語自体がシンプルに仕上がっているのもまた事実である.
この表記は絶対使うなというわけではない.場合によっては必要になることもあるので,その時は使うしかあるまい(メモリ空間の管理をOSではなく,自分で行なうプログラムを書く場合には必要になるであろう).ただ,そのような場合を除けば使うべきではない.
これで,ポインタと配列の大きな違いについては,終わりにする.後で追加事項があれば適時追加することにする.
次に本文中でwordを単位として扱った理由を述べる.まず,以下のプログラムを実行していただきたい.
/* 各型の大きさを計る */
#include <stdio.h>
main()
{
printf("int %d\n", sizeof(int));
printf("short %d\n", sizeof(short int));
printf("long %d\n", sizeof(long int));
printf("signed %d\n", sizeof(signed int));
printf("unsigned %d\n", sizeof(unsigned int));
printf("char %d\n", sizeof(char));
printf("float %d\n", sizeof(float));
printf("double %d\n", sizeof(double));
}
プログラム4 各型の大きさを計る
プログラムに関する説明は省かせていただく.問題となるのはsizeofだけであるが,これについては後日解説がある.(各書籍にも載っている)
このプログラムの実行結果は,マシン,OS,コンパイラによって異なるであろう.参考までにいくつか調べた結果を巻末(付録2)に載せるので,見ていただきたい.
このプログラムは各型の大きさをbyte単位で表示する.つまりint型が何byte必要でfloat型が何byte必要かということを提示してくれる.
すでに述べたようにメモリ空間はbyteで構成されているが,この結果を見るとすでにCの型はそれを複数個集めて処理していることがお分かり頂けるだろう.(先の説明は別にみなさんを混乱させるために書いたわけでも,ましてや騙すつもりもない)
ところで最近のコンピュータのCPUはすでに16bitsマシンさえ時代遅れとなり,今や32bitsの時代を迎えている.このCPUのビット数は普通そのマシンで扱えるint型のサイズを表わす.が,実際にはそうはならない(特にパソコンは).なぜか.それはOSのせいである.CPUは32bitsが主流になっているのに,32bits用のOSがあまり出回ってないのである.MS-DOSは16bits用OSである.(ちなみにCP/Mは8bits用OS) このため我が愛機486DX2も int型が 2bytes = 16bits となっている.
本来ならwordのビット数はCPUのビット数と同じはずであるが,使用するOSによるのでここでは,OSのビット数とし,多く出回っているOSが16bitsOSであることを考え,最小単位を1word,1word=16bits とした.なお,int型の大きさはマシン,OS,コンパイラによって変わるが,char型だけはどんな構成でも8bitsである.なぜなら,ASCIIやEBSDICのような文字コード表は8bitsで全て表現できるからである.(ただし日本語は2byte必要である)
プログラム4の結果は,もう一つ面白いことを教えてくれる.それは,ポインタ変数に対して演算を行なうとき,いくつずらすかということである.(図−13参)
ex18.
int a[10]; に対して a[5] → 先頭アドレスaに対して 5 * 2bytes = 10bytes後ろの位置. double d[30]; に対して d[5] → 先頭アドレスdに対して 5 * 8bytes = 40bytes後ろの位置.
図−13 同じ5でも実際のbyte数は異なる.ポインタ変数に対する演算でも同じである. |
さて,更にもう一つ.PL9〜PL11で軽く振れたが,Cでは”関数も値を持つ”ということを思い出していただきたい.Cは非常にシンプルな言語で,関数すら値を持つ(唯一の例外はvoid型の返り値の関数である).値を持っていて,関数名が存在するのだから,これは変数と同じ扱いが出来る.といっても関数を配列表記にすることは出来ないが,ポインタ表記は可能で,かつ”関数へのポインタ(関数の先頭アドレスを格納する変数)”も存在する.関数へのポインタについては,後日講義がある.
以上で,今回は終わりであるが,不明な点,分からないことがあったら,どしどしご質問いただきたい.
Cは非常にシンプルな言語で,他の言語ほど複雑ではない.かといって使用範囲が限られてるわけではなく,むしろ機能はたいていのことは行える程充実している.これらの機能を生かすには,ポインタ(配列)や,変数の番地と値の概念,再帰構造,レコード型(後日講義)が非常に重要である.我々としては多くの方にマスターしていただきたいので,なるべく分かり易く解説しているつもりであるが,至らぬ点も多々あるであろう.よって,よくわからない,解説の意味が不明だという場合には,(まず調べてから)御質問,御指摘をいただきたい.おそらく,市販の書と表現が違うところが多々あるであろうが,意味は同じはずである.(ただし,コンパイラ特有の解説書とは異なるかも知れない.あるコンパイラは特殊機能を多く持っていて,標準では記述できないことも可能にしてしまう.)
外国語や音楽は特に躊躇であるが,身に付けるには何度も見聞きし,慣れ親しむことが重要である.おそらく,ビックリショウに出てくるような特別な人を除いては,一度見聞きしただけでそれを生涯覚えていられる人はいまい.日頃から親しむことが,感覚を養い,理屈ぬきの知識を獲得する一番いい方法である.プログラミング言語,コンピュータについても同じで,書籍を何度も読むこと,同じ様なプログラムを(何も見ないで)何度も組むこと,例題プログラムを少し改造して実行してみてどこが違うのか考え調べることが,修得への近道であることを最後に付け加えておく.
では,また,近いうちに.
| お詫び | 前回のQ&A(Answer for H5 3/4)でPL14がアップされているような書き方をしてしまい,sysopに知らせた方もいらっしゃるようですが,実はあれは近々アップしますのでそれをご覧下さい,というつもりで書いたのです.読者の皆さん,sysopとシステム管理の方にご迷惑をかけましたことを,この場を借りてお詫びいたします.どうもすみませんでした.以後気をつけます.(zoh’) |
付録1 画像,音声データについて
まず,最初は静止画像(グラフィック)について述べる.通常パソコンは,グラフィック用のメモリエリアを持つ.これは画面上の素子一つ一つに対応している.コンピュータの仕様表に640 * 400 dot と書かれているが,このdotというのが,素子一つを表わす.簡単に言えば,この場合だと画面上に640 * 400個の点があると考えればよい.この点一つ一つがいろいろな色を発光して画面に現れる.このデータ量は膨大で,例えば素子一つが8色しか発光しないとしても 3bits * 640 * 400 = 768000bits となってしまう.なぜ3bitsかと言うと8は2進数で3bitsあれば表わすことが出来るからである.1byte = 8bitsだから.768000 / 8 = 96000bytes,1word = 16bits としても 48000words になってしまう.実際には,このデータを何らかの方法で圧縮して保存するが,膨大な量であることに変りはない.
次に音声だが,これはテープレコーダの様な磁性体に音を記録する場合を考えてみる.この記録方式をそのまま(あるいは何らかの変換方法(AD,DA変換など)で)メモリ上に持ってきることを考えればよい.ただし,このときのデータ量も膨大で,ちょっとしゃべっただけで,静止画像のデータ量を軽く越えてしまう.(PDS等で流れている音声データは,単語だけで数百バイトある)
動画も音声同様,ビデオテープの記録方式を考えてみればよい.このときのデータ量は,音声,静止画像と比べものにならないくらいの膨大な量で,2,3秒流しただけでメモリオーバーになる可能性がある.
いずれにせよ,以下の様な関係式が成り立つ.
静止画像のデータ量 < 音声のデータ量 << 動画のデータ量
付録2 各型のサイズ(単位はbyte)
486DX2 + DOS/V + BC++ Ver 3.0 WorkStation + Unix + GCC Ver 2.0
PC-9801RX21 + MS-DOS + TC Ver 2.0 X68000PROHD + Human68k + GCC
int 2 int 4
short 2 short 2
long 4 long 4
signed 2 signed 4
unsigned 2 unsigned 4
char 1 char 1
float 4 float 4
double 8 double 8
*shortとlongについては必ず short < long となるように設定される.
各マシンのCPUbit数 各OSのbit数 486DX2 32bits MS-DOS(DOS/V) 16bits PC-9801RX21 16 Unix 32 WorkStation 32 Human68k 32 X68000PROHD 32 *X68000のCPUは,外部バスが16bitであるが内部バスは32bitである.MS-DOSは16bitOSなのでCPUが32bitでもint型のサイズは16bitになってしまう.
これに対してUnixやHuman68kは32bitOSなので,int型も32bitになっている.(各コンパイラのint型のサイズは動作するOSに依存しているので,OSによって決ってしまう.LSI-Cで調べなかったのはこのためである.)